|
|
Archive for the ‘Business Rules’ Category
Sunday, November 16th, 2014
As I was reading a blog post on CQRS, Aggregate Roots, and Invariants here, I became aware of a mistake I’ve seen many developers make over the years and I thought I’d call it out real quick.
Superficial Invariants
Taken from the blog post mentioned above: “For example, an employee cannot take more annual leave than they have.”
This falls into the trap of applying mathematical thinking (which we developers possess in great quantities) to the business world. The business world isn’t that mathematical (in general), and tends to have many more shades of gray expressed as “business rules” which can, and do, change.
Rules – not invariants
Employees can’t take more annual leave than they have.
… unless their manager approves.
… but that’s only up to 2 days.
… unless their manager is a VP, and then it’s up to 5 days.
… and that negative balance will be deducted from next year’s leave.
… Oh, and if the employee leaves the company before then, then the value of those negative days will be deducted from their final paycheck.
Impact on your domain
First of all, I hope you see that this isn’t something that you would trivially implement on an Employee object.
If you read these rules more carefully, you’ll probably notice that they’re speaking about a long-running process.
First, there is a request for leave. Then there’s an approval (with certain rules) which may come sometime later. And the approval itself may not even end the process – if the balance becomes negative.
And, as you’ve probably heard me say before, you end up with sagas as your aggregate roots (see Race conditions don’t exist from 4 years ago).
And a word about Bounded Contexts
Notice that these rules don’t care very much about things like the employee’s name, phone number, email, etc. Similarly, logic that deals with that data probably doesn’t care about the number of days of leave an employee takes.
In other words, these sets of data and logic can be said to belong to different Sub-Domains (in DDD terminology).
As such, it can make sense to take the annual leave logic and put it in a bounded context separate from the one responsible for the contact info.
In closing
In many of the samples and blog posts I see online, an overly simplified problem domain is implemented showing how the given implementation technique would be applied.
The problem is that developers then use that implementation technique as a “cookie cutter”, trying to fit real-world requirements into it, and then end up making a pretty big mess.
The more you delve into real-world requirements of business domains, the less you’ll see of mathematical invariants (unless, maybe, you’re building a physics engine for a game or something) and the more you’ll see long-running processes unfolding in front of you.
Regardless of whether you use NServiceBus sagas or not, start looking at the world as dynamic long-running processes rather than static noun-centric entities.
Posted in Business Rules, CQRS, Workflow | 12 Comments »
Wednesday, April 2nd, 2014
 So, I’ve been a bad presenter. So, I’ve been a bad presenter.
I’ve given my Programming in 4D talk already several times and I haven’t yet uploaded the code for it.
And seeing as I’m going to be giving it again today (at the DevWeek conference in London), I figured that I should finally get my act together and put it online.
Interestingly enough, the other conferences I’ve spoken at either didn’t record it or didn’t put the recording online. Hopefully DevWeek will do better <FingersCrossed/>.
The overall solution
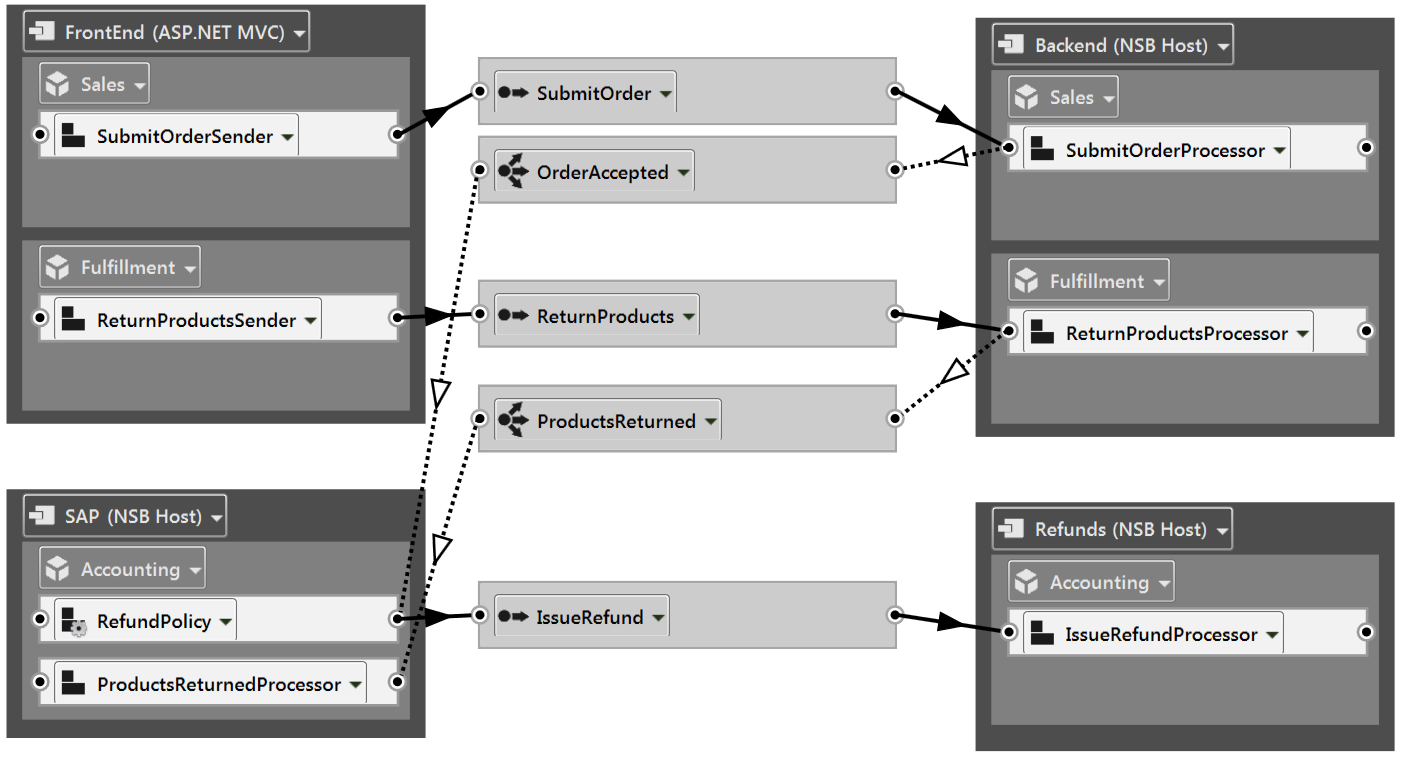
The scenario I talk about in this presentation is (again) a standard one in the world of retail: customers who want to return products that they’ve purchased and get a refund.
I’ve used our new ServiceMatrix tooling to model the solution like this (click for a larger image):

If you’d like to download the complete solution, click here.
Now, we’re going to focus on the RefundPolicy object that you can see towards the bottom left.
The Refund Policy
So, in this scenario, what we’re going to implement is a process whereby if you return your products within 30 days of the purchase, you’ll receive a 100% refund; if you return your products within 60 days you’ll receive a 50% refund, and anything longer than that and no refund for you.
Here’s the code:
public class RefundPolicy : Saga<RefundPolicySagaData>,
IAmStartedByMessages<OrderAccepted>,
IHandleMessages<ProductsReturned>,
IHandleTimeouts<Percent>,
IHandleSagaNotFound
{
public void Handle(OrderAccepted message)
{
Data.OrderId = message.OrderId;
Console.WriteLine("OrderAccepted");
Data.Percent = 100;
RequestTimeout(TimeSpan.FromDays(30), 50.Percent());
RequestTimeout(TimeSpan.FromDays(60), 0.Percent());
}
public void Handle(ProductsReturned message)
{
Console.WriteLine("ProductsReturned");
Bus.Send<IssueRefund>(m => m.Percent = Data.Percent);
MarkAsComplete();
}
public override void ConfigureHowToFindSaga()
{
ConfigureMapping<ProductsReturned>(m => m.OrderId).ToSaga(s => s.OrderId);
}
public void Timeout(Percent state)
{
Console.WriteLine("Timeout");
Data.Percent = state;
if (state == 0)
MarkAsComplete();
}
public void Handle(object message)
{
if (message is ProductsReturned)
Console.WriteLine("No refund for you");
}
}
public class RefundPolicySagaData : ContainSagaData
{
[Unique]
public int OrderId { get; set; }
public Percent Percent { get; set; }
}
And what’s so good about that?
Well, not to steal my own thunder and give you a reason not to watch the video when it comes out, the trick is in the two RequestTimeout calls that are invoked when an OrderAccepted message arrives. You see, what that does is that it takes the data that defines the behavior of the refund policy and persists that via a queue, which will play back the data to our object according to the defined schedule.
This way, if/when the business decides to change the rules (say, reducing the timeframes to 20 days and 40 days), that will only affect users who are placing new purchases. The customers who made a purchase 50 days earlier (when the rules were still 30/60) will get the correct behavior applied to them.
Next steps
Of course, nobody would want a developer to have to open this code and change it in order to make a simple change like 30/60 -> 20/40, so we could externalize the data by creating a dictionary property on the saga where the key is the TimeSpan and the value is the Percent. Then, we could pull those values from either a config file or database and inject them into the property on the saga.
Here’s how the code of the saga would change:
public class RefundPolicy : Saga<RefundPolicySagaData>,
IAmStartedByMessages<OrderAccepted>,
IHandleMessages<ProductsReturned>,
IHandleTimeouts<Percent>,
IHandleSagaNotFound
{
public Dictionary<TimeSpan, Percent> DataDefinitions { get; set; }
partial void HandleImplementation(OrderAccepted message)
{
Data.OrderId = message.OrderId;
Console.WriteLine("OrderAccepted");
Data.Percent = 100;
foreach(var kv in DataDefinitions)
RequestTimeout(kv.Key, kv.Value);
}
And the code to do the property injection would look like this:
public class RefundPolicyDataConfigurator : INeedInitialization
{
public void Init()
{
Dictionary<TimeSpan, Percent> data = null /* get from config instead */;
Configure.Instance.Configurer
.ConfigureProperty<RefundPolicy>(p => p.DataDefinitions, data);
}
}
Classes the implement INeedInitialization are invoked at process startup, and that call to ConfigureProperty instructs the container to set the DataDefinitions property of our RefundPolicy every time it is resolved (which is on every message).
In closing
We now have a solution which allows non-developers to make changes to the refund policy definitions without requiring us to deploy any new code to production. Also, any changes that are made will preserve the promises we made to our users in the past.
Of course, if you want changes to rules to impact all users immediately, this approach wouldn’t be so good.
Again, if you’d like to download the complete solution, the code is here, and if it wasn’t already obvious, this code makes use of NServiceBus quite heavily.
When the recording comes online, I’ll update this post with a link as well as do another blog post.
Hope you like it.
Posted in Business Rules, Messaging, Modeling, NServiceBus, Versioning | 7 Comments »
Sunday, November 4th, 2012
Feeling a little bit rant-y today, as I just saw some more abuse of remote calls, this time on the Java side of things.
JPA is the Java Persistence API – a kind of ORM, as you’d expect. Luckily, a lot of the web services stuff was already on the way out by the time that EclipseLink DBWS came out. DBWS allowed you to expose database artifacts as web services.
I mean, it’s not like we have any other interoperable ways of accessing data, right?
Anyway, like I said, that didn’t take off, but now they’re reinventing it – this time with REST!
In case you had any doubts, REST is pure awesomeness and adding it to anything else makes it awesome too. Lest anybody take this out of context (it’s happened before), I’m being sarcastic.
Here it is.
God knows they couldn’t let Microsoft totally dominate this area with OData coming out quite some time ago. In case you were wondering, OData was designed to provide standard CRUD access of a data source over HTTP.
Of course, none of these support any transactions so if you actually wanted to do some meaningful business logic on top of this CRUD, you wouldn’t have any consistency. And, let’s face it, if you’re not doing any meaningful business logic, just basic persistence, you just do it. That problem’s been solved a long time ago.
Can we please stop reinventing SQL already?
Posted in Architecture, Business Rules, Data Access, Databases, REST, Web Services | 3 Comments »
Monday, July 9th, 2012
 Following on my last post called UI composition techniques for correct service boundaries, one commentor didn’t seem to like the approach I described saying: Following on my last post called UI composition techniques for correct service boundaries, one commentor didn’t seem to like the approach I described saying:
“I’m sorry, but with all due respect I must strongly disagree. You haven’t avoided any orchestration work at all, you’ve just moved it in to client side script!
How are you going to deal with the scenario that one of the service calls fails? Say a failed credit card payment, or no more rooms left? In more javascript??
I would much rather take the less brittle approach of introducing an orchestration service. Like it or not, however trivial it may be, there is a relationship between these services, if one call fails, they both fail. This should be reflected in the architecture, not hidden in javascript. With an orchestration service you also either get transactions for free provided by infrastructure, or alternatively if the underlying service doesnt support this, explicit and unit testable control over recovery.”
Since this is a common point of view, I thought I’d take the time to explain a bit more.
Let’s start at a fairly high level.
On failures
I’ve talked many times in the past about how to handle technical causes for failure like server crashes, database deadlocks, and even deserialization exceptions. Messaging and queuing solutions like NServiceBus can help overcome these issues such that things don’t actually fail – they just take a little longer to succeed.
On the logical side of things, the CQRS patterns I talk about describe an approach where aggressive client-side validation is done to prevent almost all logical causes for failure. The only thing that can’t be mitigated client-side are race conditions resulting in actions taken by other users at the same time.
In short, it really is uncommon for things to fail when being processed server-side.
Back to the specific example
The concerns raised in the comment specifically talked about a failed credit card payment or no rooms left in the hotel, so let’s start with the credit card thing:
In my last post I talked about collecting guest and credit card information from the user as a part of the “checkout” process when making a reservation for a hotel room. Just to be clear – there is a final “confirm your reservation” step that happens after all information has been collected.
What this means is that we aren’t actually charging the customer’s card when we collect that data, therefore there is no real issue with a failed credit card payment that needs to be handled by the client-side javascript. When the customer confirms their reservation, yes, there might be a failure when charging the card though there are only some specific types of rates for which the hotel charges your card when you make a reservation.
In general, failed credit card payments are handled pretty much the same way for all ecommerce – an email is sent to the customer asking for an alternative form of payment, also saying that their purchase won’t be processed until payment is made.
In any case, it is only after the reservation is placed that the responsible service would publish an event about that. The service which collected the credit card information would be subscribed to that event and initiate the charge of the card when that event arrives (or not, depending on the rate rules mentioned).
With regards to there not being any rooms left, well, first of all, there’s overbooking – hotels accept more reservations than rooms available because they know that customers sometimes need to cancel, and some just don’t show up. Secondly, there is a manual compensation process if more people show up than there are actual rooms to put them in. In some cases, a hotel will bump you up to a higher class of room (assuming there aren’t too many reservations for those), and in others they will call a “partner” hotel nearby and put you up there instead.
In summary
While arguments can be made that yes, these issues have been addressed in this specific example, there may be other domains where it is not possible to do these kinds of “tricks”. Although I do agree with that in theory, I’ve spent the better part of 5 years travelling around the world talking to hundreds of people in quite a few business domains, and every single time I’ve found it possible to apply these principles.
In short, the use of UI composition allows services to collect their own data, making it so anything outside that service doesn’t depend on those data structures which makes both development and versioning much easier. Technical failure conditions can be mitigated at infrastructure levels in most cases and other business logic concerns can be addressed asynchronously with respect to the data collection.
Give it a try.
Posted in Architecture, Autonomous Services, Business Rules, EDA, Reliability, SOA | 27 Comments »
Thursday, March 29th, 2012
Update – clarification post here.
 I was on a call recently with the Advisory Board for the Microsoft Patterns & Practices (P&P) CQRS Journey project where they were showing the current state of their development. Towards the middle of the call, I mentioned that I found there to be too many concerns in one place and that I had expected there to be a division into multiple sub-domains/bounded contexts/business components (BCs). The answer was that they hadn’t gotten to the other areas yet and that’s why at that point in time there was only one BC. I was on a call recently with the Advisory Board for the Microsoft Patterns & Practices (P&P) CQRS Journey project where they were showing the current state of their development. Towards the middle of the call, I mentioned that I found there to be too many concerns in one place and that I had expected there to be a division into multiple sub-domains/bounded contexts/business components (BCs). The answer was that they hadn’t gotten to the other areas yet and that’s why at that point in time there was only one BC.
The conversation got a bit derailed at that point, and I was asked how I would do it (though not quite as politely), ultimately leading to my tweeting this:
I think I got over 50 people who wanted in on this, while some of them urged me to work with P&P rather than separately. I think I’ll do both, hopefully resulting in two implementations that can be compared – one based on Azure (done by P&P) and the other based on NServiceBus (done by my guys). Who do you think is more worried 😉
But first things first
The fundamental flaw that I see happening with many software projects (including the P&P CQRS effort) is that not enough time is spent to understand the underlying business objectives – the thinking behind the use cases / user stories. Developers assume behavior is “like” that of another/similar domain – when the difference in the details matter a lot. That often leads to software boundaries that aren’t properly aligned with those of the business.
The effects of this lack of alignment may be felt only much later in the project, when we get a requirement that just doesn’t fit the architecture we’ve set up. I’ve blogged about the symptoms of this problem about 2 years ago in my post Non-functional architectural woes.
We need to get into the nitty-gritty of our problem domain to find out what makes it special.
Not all e-commerce is equal
Anytime somebody is going to make a purchase online, developers immediately create some kind of “order” entity with a bunch of “order lines”, just like they read about in all the blog posts and books. Then, all sorts of other behavior are shoe-horned around those entities and… voila, a working system.
The domain of conferences is different – we don’t actually ship products when people register so payment concerns are very different. If our company is purchasing 5 tickets to the conference, the number of people (and which specific people) that eventually go to the conference may be very different than the people we had originally registered – there doesn’t tend to be that kind of volatility in traditional B2C retail (like selling books to people online).
It’s also quite likely that if a company is sending many people to a conference that they wouldn’t be paying by credit card – invoicing and payment may happen much later. That is no reason to block registration from completing.
Not all registration systems are equal
I understand how people can look at systems like TicketMaster and use that as a model for this system but, once again, the differences in the domain matter.
First of all, most people don’t purchase movie tickets weeks in advance – conference tickets do go on sale that far in advance. Second, if the movie you want to go to is sold out this week, no big deal, you’ll see it next week – conferences are more of a one-time/yearly deal. Third, you usually go to the movies with family/friends – if you can’t get tickets for everyone, you’ll go next week. When it comes to conferences, there is no “next week”, so whoever can go, does. Also, attendees going to a conference together are usually coworkers, not family – there are less qualms about leaving someone behind.
This is already leading us to a model where we should not view a group registration as a single success or failure affair. This will have an impact on the commands, events, and transactions that flow through our system.
In any case where people are reserving something far in advance, there is a high likelihood of cancellations. This is similar to the domain of hotels/hospitality where you can cancel your reservation up to N days before your arrival at no charge. This also tends to influence the payment structure – we’d rather not have to return people’s money as there can be per-transaction charges for that, instead delaying payment can make sense.
Similar to how hotels overbook by a certain amount (to offset cancellations), our conference might look at doing something similar. The difference is that in the case of a hotel, the guest will likely just book a room in a different hotel in the case the first hotel was fully booked. This probably won’t happen with a conference.
For that reason, we want to remember who wanted to come to our conference even when we thought we were full. You see, our best chance of filling a seat that opened up due to a cancellation is by a person who wanted to register before. What we need here is a waiting list – something that doesn’t make the same kind of sense for hotels or airlines (although airlines do use waiting lists, just that that is usually exposed to travel agents and not to travelers booking online).
First-come, first-served – fairness
The traditional developer thinking about systems is rooted in synchronous and sequential processes. In attempting to give a good user experience, developers want to give the user final confirmation as quickly as possible – whether that’s success or failure.
This results in a first-come, first-served user interaction model – whichever user registers in our conference management system first, the better the chance they’ll get what they want. That sounds like a pretty fair system, the only thing is that fairness was not a requirement.
In the real world, if people are standing in line for tickets, they’d get really upset if the tellers decided somewhat arbitrarily to serve people in the back of the line before those in the front. The great thing about online systems is that nobody can see the “virtual line” – the system can be as unfair as we like and there isn’t a real way for the users to know that this is happening.
Why be unfair?
While conferences, theaters, and airlines all want to have all seats filled, the difference between the ongoing models of airlines and theaters and the once-a-year model of the conference influence how sales are done. Some companies send a lot of employees to our conference so we want to give them preference in registration. This is area that we have the most leverage over – when it comes to the masses who arrive in ones and twos, there’s not very much we can do. It makes sense to bend over backwards for a large group, but not for a small one. A commitment from a large company tends to mean more than that from a small one.
If Boeing has already registered 70 people to your conference and now wants to send 5 more, are you really going to tell them “sorry, we’re fully booked”, or are you going to do everything in your power to keep them happy so that next year they’ll want to keep working with you? Wouldn’t it be nice if you could “unregister” some people to make room for the Beoing guys.
Now, you can’t necessarily do this up until the last minute, but potentially 2 weeks (or whatever) before the event could be reasonable, leaving people the ability to cancel flights and hotels without charges (assuming we tell them during registration that they should buy refundable plane tickets).
The easiest way to “unregister” someone is to not tell them that their registration was confirmed. In short, 2 weeks before the start of the event we finalize all registrations deciding (based on our internal priority) who gets in and who doesn’t. We may have logic that decides to immediately finalize registration from Boeing (and other select customers) without waiting until 2 weeks before the event.
Just don’t look TOO unfair
Appearance is everything. Perception matters. You don’t want to get a reputation for being unfair.
So when we open registration, we can allow the first N people to bypass our waiting list and get accepted right away (payment still needing to be handled later). At that point, you can start moving new registrations through the waiting list.
The thing is, nobody knows that you aren’t actually full at that point 🙂
Influences on architecture
I hope you’re getting the impression that this collection of scenarios is going to have a big impact on the design. It indicates to us which parts of the business need to be 100% consistent with each other and which parts can be eventually consistent – ultimately defining where one bounded context stops and another begins. This has a direct impact on the events that we’d end up with – who would publish what, and how many others would subscribe to it.
I know some people will look at the above scenarios and say “but what if the requirements were different?”. The thing is that not all requirements are created equal. In working with our business stakeholders, we need to identify which elements are stable and which are potentially volatile and, yes, that’ll be different in each project. We want to align the main boundaries of our software with the stable business elements.
And don’t even try to create a system so flexible that it could handle any new requirement without any architectural changes – down that path lies madness. User-defined custom fields used in user-defined custom workflows, all of it appearing in reports with sorting, filtering, and grouping. You might as well give your users Visual Studio.
Back to P&P
I don’t know if P&P will adopt this set of requirements for their CQRS Journey. The thing here is that we can see the collaborative nature of the domain quite clearly – multiple actors working in parallel where the decisions of one affect the outcomes of another.
The requirements that I’ve seen being handled in the CQRS Journey so far don’t seem complicated enough to justify anything more than a 2-tier architecture – it’s feeling somewhat over-engineered right now. I know that people in the community see other benefits to CQRS but I’ll have to put up a separate blog post describing why there are other better solutions than CQRS most of the time.
Anyway, I’m willing to see how things progress and tweak these requirements (up to a point) so that both the NServiceBus solution and the Azure solution are addressing the same problem.
In closing
Occasionally I hear people still raising the agile mantra against Big Design/Requirements Up Front. The thing is that Agile Manifesto never said to intentionally bury your head in the sand with regards to the purpose of the system. It was a push-back against spending months in analysis without anything but documents coming out, but the goal was to reach a middle ground. Nobody ever said “no design up-front” or “no requirements up front”.
I’m going to try to work with both P&P and the alumni of my Advanced Distributed Systems Design course to come up with simplest possible solution that addresses the requirements (functional and non-functional).
Hope you’ll find this journey interesting.
Update – clarification post here.
Posted in Architecture, Business Rules, CQRS | 12 Comments »
Monday, March 5th, 2012
Recently I’ve started talking more about modeling and its relation to the real world.
 Here’s where it all starts from: Here’s where it all starts from:
Don’t try to model the real world, it doesn’t exist.
I know that that sounds like a very Matrix-y kind of statement, so let me explain.
The “Real” World
The problem with the “real” world is that you are limited by the laws of physics. The thing is that somewhere along the history of software development, we got this idea that if only the structure of our software represented physical reality, then our software would be maintainable, flexible, robust, … in short, good.
 The thing is that a single physical entity can have multiple meanings to various stakeholders. The thing is that a single physical entity can have multiple meanings to various stakeholders.
Let’s look at something simple, like a glass:
From a developer’s perspective we might call that a Product and not think very much more of it. We’d be happy that we could come up with a single abstraction that allowed us to model all the different kinds of products the same way.
Yet, in talking with our business stakeholders, one might call it inventory, another might call it a liability (think of breakage requiring insurance), and another call it merchandise. The important thing to note is that the data relevant to each of those meanings is so different from one stakeholder to another.
And that brings me to “customer”
One of my least favorite entities – a lingering symptom of the Northwind disease.
When someone walks into your store for the first time (whether that store is physical or virtual), are they a customer? Even if they haven’t ever bought anything? Even if you don’t know their name? Are they even a User then? I mean, it’s not like we’re going to force people to login (or create an account) just to browse the site, right? A term like Visitor, Prospect, or Lead sounds like it would describe this type of concept better.
After wandering around your store for a while, they come up to you and ask for help finding something. If this pattern repeated itself over and over again for the same category of item, would that be meaningful to the business? Don’t you think that should be modeled? I hope your answers are yes, and yes. This is the domain of merchandising, and seems more related to Visitors than to Customers.
Let’s say your selling to other businesses rather than to consumers. In the B2B space, it is common not to receive payment for goods or services for some time – you might have heard terms like Net30, which means you will be paid up to 30 days later (in some cases, this may be from the end of the month of the invoice rather than the date of the invoice).
If you talk to the business folks in charge of these scenarios, you’ll hear them talk about Accounts Payable and Accounts Receivable. Yep, they are the accountants. If you were to go about building a DDD Ubiquitous Language, it sounds like the term Account would be a better choice than Customer. The thing is that accountants use the same language regardless of how quickly an account is settled – like if payment is done by credit card at the time of purchase.
There is no Customer.
There is no Product.
The same goes for so many other problem domains.
I know it feels counter-intuitive to not have a single class representing a single physical thing. It feels like it’s the exact opposite of Domain-Driven Design. It feels anti-object-oriented. But remember, most stakeholders you talk to don’t focus on the physical elements either.
The one thing left to be modeled from “reality”
And that’s identity.
It would be most accurate to say that the physical thing you perceive is nothing more than identity serving to correlate all the separate business concerns to each other. It’s this ID that ties the Visitor on the site, to the Account, to the Addressee (for shipment).
These IDs are needed primarily for reporting and UI reasons – it isn’t likely to have a business action operate on entities correlated this way in the same transaction.
Nouns, Verbs, and Reality
In building your ubiquitous language, look past the nouns and verbs visible on the surface.
Watch out for statements like “in reality…” and “in the real world…” as they are really just one person’s interpretation of their perception of reality. Not one of us is able to see reality clearly – it’s all just perceptions. Recognize that, like models, all perceptions are wrong, but some may be useful.
Model the perceptions – at least you can have first hand experience of those.
Forget about reality – all that exists is perceptions.
In closing
Transcend the physical.
In software there is no gravity, no mass, and as many dimensions as you choose to create.
Break free of the Matrix.
You are the god of your software.
Posted in Architecture, Business Rules, DDD, OO | 15 Comments »
Sunday, September 18th, 2011
One of the things that surprises some developers that I talk to is that you don’t always get consistency even with end-to-end synchronous communication and a single database. This goes beyond things like isolation levels that some developers are aware of and is particularly significant in multi-user collaborative domains.
The problem
Let’s start with an image to describe the scenario:

Image 1. 3 transactions working in parallel on 3 entities
The main issue we have here is that the values transaction 2 gets for A and B are those from T0 – before either transaction 1 or 3 completed. The reason this is an issue is that these old values (usually together with some message data) are used to calculate what the new state of C should be.
Traditional optimistic concurrency techniques won’t detect any problem if we don’t touch A or B in transaction 2.
In short, systems today are causing inconsistency.
Some solutions
1. Don’t have transactions which operate on multiple entities (which probably isn’t possible for some of your most important business logic).
2. Turn on multi-version concurrency control – this is called snapshot isolation in MS Sql Server.
Yes, you need to turn it on. It’s off by default.
The good news is that this will stop the writing of inconsistent data to your database.
The bad news is that it will probably cause your system many more exceptions when going to persist.
For those of you who are using transaction messaging with automatic retrying, this will end up as “just” a performance problem (unless you follow the recommendations below). For those of you who are using regular web/wcf services (over tcp/http), you’re “cross cutting” exception management will likely end up discarding all the data submitted in those requests (but since that’s what you’re doing when you run into deadlocks this shouldn’t be news to you).
The solution to the performance issues
Eventual consistency.
Funny isn’t it – all those people who were afraid of eventual consistency got inconsistency instead.
Also, it’s not enough to just have eventual consistency (like between the command and query sides of CQRS). You need to drastically decrease the size of your entities. And the best way of doing that is to partition those entities across multiple business services (also known in DDD lingo as Bounded Contexts) each with its own database.
This is yet another reason why I say that CQRS shouldn’t be the top level architectural breakdown. Very useful within a given business service, yes – though sometimes as small as just some sagas.
Next steps
It may seem unusual that the title of this post implies that SOA is the solution, yet the content clearly states that traditional HTTP-based web services are a problem. Even REST wouldn’t change matters as it doesn’t influence how transactions are managed against a database.
The SOA solution I’m talking about here is the one I’ve spent the last several years blogging about. It’s a different style of SOA which has services stretch up to contain parts of the UI as well as down to contain parts of the database, resulting in a composite UI and multiple databases. This is a drastically different approach than much of the literature on the topic – especially Thomas Erl’s books.
Unfortunately there isn’t a book out there with all of this in it (that I’ve found), and I’m afraid that with my schedule (and family) writing a book is pretty much out of the question. Let’s face it – I’m barely finding time to blog.
The one thing I’m trying to do more of is provide training on these topics. I’ve just finished a course in London, doing another this week in Aarhus Denmark, and another next month in San Francisco (which is now sold out). The next openings this year will be in Stockholm, London; Sydney Australia and Austin Texas will be coming in January of next year. I’ll be coming over to the US more next year so if you missed San Francisco, keep an eye out.
I wish there was more I could do, but I’m only one guy.
Hmm, maybe it’s time to change that.
Posted in Architecture, Autonomous Services, Business Rules, CQRS, Data Access, Databases, DDD, Reliability, SOA | 12 Comments »
Wednesday, July 13th, 2011
It isn’t uncommon for me to have a client or student at one of my courses ask me about some kind of workflow tool. This could be Microsoft Workflow Foundation, BizTalk, K2, or some kind of BPEL/orchestration engine. The question usually revolves around using this tool for all workflows in the system as opposed to the SOA-EDA-style publish/subscribe approach I espouse.
The question
The main touted benefit of these workflow-centric architectures is that we don’t have to change the code of the system in order to change its behavior resulting in ultimate flexibility!
Some of you may have already gone down this path and are shaking your heads remembering how your particular road to hell was paved with the exact same good intentions.
Let me explain why these things tend to go horribly wrong.
What’s behind the curtain
It starts with the very nature of workflow – a flow chart, is procedural in nature. First do this, then that, if this, then that, etc. As we’ve experienced first hand in our industry, procedural programming is fine for smaller problems but isn’t powerful enough to handle larger problems. That’s why we’ve come up with object-oriented programming.
I have yet to see an object-oriented workflow drag-and-drop engine. Yes, it works great for simple demo-ware apps. But if you try to through your most complex and volatile business logic at it, it will become a big tangled ball of spaghetti – just like if you were using text rather than pictures to code it.
And that’s one of the fundamental fallacies about these tools – you are still writing code. The fact that it doesn’t look like the rest of your code doesn’t change that fact. Changing the definition of your workflow in the tool IS changing your code.
On productivity
Sometimes people mention how much more productive it would be to use these tools than to write the code “by hand”. Occasionally I hear about an attempt to have “the business” use these tools to change the workflows themselves – without the involvement of developers (“imagine how much faster we could go without those pesky developers!”).
For those of us who have experienced this first-hand, we know that’s all wrong.
If “the business” is changing the workflows without developer involvement, invariably something breaks, and then they don’t know what to do. They haven’t been trained to think the way that developers have – they don’t really know how to debug. So the developers are brought back in anyway and from that point on, the business is once again giving requirements and the devs are the one implementing it.
Now when it comes to developer productivity, I can tell you that the keyboard is at least 10x more productive than the mouse. I can bang out an if statement in code much faster than draggy-dropping a diamond on the canvas, and two other activities for each side of the clause.
On maintainability
Sometimes the visualization of the workflow is presented as being much more maintainable than “regular code”.
When these workflows get to be to big/nested/reused, it ends up looking like the wiring diagram of an Intel chip (or worse). Check out the following diagram taken from the DailyWTF on a customer friendly system:

The bigger these get, the less maintainable they are.
Now, some would push back on this saying that a method with 10,000 lines of code in it may be just as bad, if not worse. The thing is that these workflow tools guide developers down a path where it is very likely to end up with big, monolithic, procedural, nested code. When working in real code, we know we need to take responsibility for the cleanliness of our code using object-orientation, patterns, etc and refactoring things when they get too messy.
Here is where I’d bring up the SOA/pub-sub approach as an alternative – there is no longer this idea of a centralized anything. You have small pieces of code, each encapsulating a single business responsibility, working in concert with each other – reacting to each others events.
Productivity take 2: testing and version control
If you’re going to take your most complex and volatile business logic and put it into these workflow tools, have you thought about how your going to test it? How do you know that it works correctly? It tends to be VERY difficult to unit-test these kinds of workflows.
When a developer is implementing a change request, how do they know what other workflows might have been broken? Do they have to manually go through each and every scenario in the system to find out? How’s that for productivity?
Assuming something did break and the developer wants to see a diff – what’s different in the new workflow from the old one, what would that look like? When working with a team, the ability to diff and merge code is at the base of the overall team productivity.
What would happen to your team if you couldn’t diff or merge code anymore?
In this day and age, it should be considered irresponsible to develop without these version control basics.
In closing
There are some cases where these tools might make sense, but those tend to be much more rare than you’d expect (and there are usually better alternatives anyway). Regardless, the architectural analysis should start without the assumption of centralized workflow, database, or centralized anything for that matter.
If someone tries to push one of these tools/architectures on you, don’t walk away – run!
Posted in Architecture, Autonomous Services, BizTalk, BPM, Business Rules, EDA, OO, Pub/Sub, SOA, Testing, Workflow | 54 Comments »
Saturday, March 5th, 2011
One of the things I cover early on in my course is the problem with traditional layered architecture driving people to create a business logic layer made up of a bunch of inter-related entities. I see this happening a lot, even though nowadays people are calling that bunch of inter-related entities a “domain model”.
Let me just say this upfront – most inter-related entity models are NOT a domain model.
Here’s why: most transactions don’t respect entity boundaries.
That being said, you don’t always need a domain model.
The domain model pattern’s context is “if you have complicated and everchanging business rules” – right there on page 119 of Patterns of Enterprise Application Architecture.
Persisting the customer’s first name, last name, and middle initial – and later reading and showing that data does not sound either complicated or that it is really going to change that much.
Then there are things like credit limits, that may be on the customer entity as well. It is likely that there are business requirements that expect that value to be consistent with the total value of unpaid orders – data that comes from other entities.
The problem that is created is one of throughput.
Since databases lock an entire row/entity at a time, if one transaction is changing the customer’s first name, the database would block another transaction that tried to change the same customer’s credit limit.
The bigger your entities, the more transactions will likely need to operate on them in parallel, the slower your system will get as the number of transactions increases. This feeds back in on itself as often those blocked transactions will have operated already on some other entity, leaving those locked for longer periods of times, blocking even more transactions.
And the absurd thing is that the business never demanded that the customer’s first name be consistent with the credit limit.
What if we didn’t have a single Customer entity?
What if we had one that contained first name, last name, middle initial and another that contained things like credit limit, status, and risk rating. These entities would be correlated by the same ID, but could be stored in separate tables in the database. That would do away with much of the cascading locking effects drastically improving our throughput as load increases.
And you know what? That division would still respect the 3rd normal form.
Which of these entities do you think would be classified by the business under the “complicated and everchanging rules” category?
And for those entities that are just about data persistence – do you think it’s justified to use 3 tiers? Do we really need a view model which we transform to data transfer objects which we transform to domain objects which we transform to relational tables and then all the way back? Wouldn’t some simpler 2-tier programming suffice – dare I say datasets? Ruby on Rails?
Are we ready to leave behind the assumption that all elements of a given layer must be built the same way?
Posted in Architecture, Business Rules, Data Access, Databases, DataSets, DDD, OO | 6 Comments »
Tuesday, August 31st, 2010
 Not in the business world anyway. Not in the business world anyway.
The problem is that, as software developers, we’re all too quick to accept them at face value. We don’t question the requirements – in all fairness, it was never our job to do so. We were the ones that implemented them, preferably quickly.
For example
Let’s say we get the requirement the following requirements:
1. If the order was already shipped, don’t let the user cancel the order.
2. If the order was already cancelled, don’t let the user ship the order.
The race condition here is when we have two users who are looking at the same order, which is neither cancelled nor shipped yet, and each submits a command – one to ship the order, the other to cancel it.
In these cases, the code is simple – just an if statement before performing the relevant command.
So what’s the problem
A microsecond difference in timing shouldn’t make a difference to core business behaviors. Which means that we’ve actually got here is a bug in the requirements. Users are actually dictating solutions here rather than requirements.
Let’s ask our stakeholders, “why shouldn’t we let users cancel a shipped order? I mean, the users don’t want the products.”
And the stakeholders would respond with something like, “well, we don’t want to refund the user’s money then. Or, at least, not all their money. Well, maybe if they return the products in their original packaging, *then* we could give a full refund.”
And as we drilled deeper, “when do refunds need to be given? Right away, in the same transaction?”
The stakeholders would explain, “no, refunds don’t need to be given right away.”
It turns out we were missing the concept of a refund, as well as assuming that all things needed to be processed and enforced immediately. Once we dug into the requirements, we found that there is actually plenty of time to allow both transactions to go through. We just need to add some checks during shipping’s long-running process to see if the order was cancelled, and then to cut the process short.
So is everything a long-running process then?
That’s actually a fair question – long-running processes are a lot more common than at first appears.
What we’re seeing is that cancellation is now a command that has no reason to fail – just like CQRS tells us. When this command is performed, it publishes the OrderCancelled event, which the billing service subscribes to.
Billing then starts a long-running process (a saga, in NServiceBus lingo), also listening to events from the shipping process, ultimately making a decision when a refund should be given, and for how much.
Deeper business analysis
As we discuss matters more with our business stakeholders, we hear that most orders are actually cancelled within an hour of being submitted. It is quite rare for orders to be cancelled days later.
In which case, we could look at modeling the acceptance of an order as a long-running process itself.
When a user places an order, we don’t immediately publish an event indicating the acceptance of an order, instead a saga is kicked off – which opens up a timeout for an hour later. If a cancellation command arrives during that period of time, the user gets a full refund (seeing as we didn’t charge anything since billing didn’t get the accepted event to begin with), and the saga just shuts itself down. If the timeout occurs an hour later, and the saga didn’t get a cancel command, then the order is actually accepted and the event is published.
Yes, sagas are everywhere, once you learn to see with business eyes, and no race conditions are left.
In closing
Any time you see requirements that indicate a race condition, dig deeper.
What you’re likely to find are some additional business concepts as well as the introduction of time and the creation of long-running business processes. The implementation at that point will pivot from being trivial if-statements to being richer sagas.
Keep an eye out.
Posted in Architecture, BPM, Business Rules, CQRS, NServiceBus, Pub/Sub, Workflow | 35 Comments »
|
|
|
Recommendations
Bryan Wheeler, Director Platform Development at msnbc.com
“ Udi Dahan is the real deal.We brought him on site to give our development staff the 5-day “Advanced Distributed System Design” training. The course profoundly changed our understanding and approach to SOA and distributed systems. Consider some of the evidence: 1. Months later, developers still make allusions to concepts learned in the course nearly every day 2. One of our developers went home and made her husband (a developer at another company) sign up for the course at a subsequent date/venue 3. Based on what we learned, we’ve made constant improvements to our architecture that have helped us to adapt to our ever changing business domain at scale and speed If you have the opportunity to receive the training, you will make a substantial paradigm shift. If I were to do the whole thing over again, I’d start the week by playing the clip from the Matrix where Morpheus offers Neo the choice between the red and blue pills. Once you make the intellectual leap, you’ll never look at distributed systems the same way. Beyond the training, we were able to spend some time with Udi discussing issues unique to our business domain. Because Udi is a rare combination of a big picture thinker and a low level doer, he can quickly hone in on various issues and quickly make good (if not startling) recommendations to help solve tough technical issues.” November 11, 2010
 Sam Gentile, Independent WCF & SOA Expert
Sam Gentile, Independent WCF & SOA Expert
“Udi, one of the great minds in this area. A man I respect immensely.”
 Ian Robinson, Principal Consultant at ThoughtWorks
Ian Robinson, Principal Consultant at ThoughtWorks
"Your blog and articles have been enormously useful in shaping, testing and refining my own approach to delivering on SOA initiatives over the last few years. Over and against a certain 3-layer-application-architecture-blown-out-to- distributed-proportions school of SOA, your writing, steers a far more valuable course."
 Shy Cohen, Senior Program Manager at Microsoft
Shy Cohen, Senior Program Manager at Microsoft
“Udi is a world renowned software architect and speaker. I met Udi at a conference that we were both speaking at, and immediately recognized his keen insight and razor-sharp intellect. Our shared passion for SOA and the advancement of its practice launched a discussion that lasted into the small hours of the night. It was evident through that discussion that Udi is one of the most knowledgeable people in the SOA space. It was also clear why – Udi does not settle for mediocrity, and seeks to fully understand (or define) the logic and principles behind things. Humble yet uncompromising, Udi is a pleasure to interact with.”
 Glenn Block, Senior Program Manager - WCF at Microsoft
Glenn Block, Senior Program Manager - WCF at Microsoft
“I have known Udi for many years having attended his workshops and having several personal interactions including working with him when we were building our Composite Application Guidance in patterns & practices. What impresses me about Udi is his deep insight into how to address business problems through sound architecture. Backed by many years of building mission critical real world distributed systems it is no wonder that Udi is the best at what he does. When customers have deep issues with their system design, I point them Udi's way.”
 Karl Wannenmacher, Senior Lead Expert at Frequentis AG
Karl Wannenmacher, Senior Lead Expert at Frequentis AG
“I have been following Udi’s blog and podcasts since 2007. I’m convinced that he is one of the most knowledgeable and experienced people in the field of SOA, EDA and large scale systems.
Udi helped Frequentis to design a major subsystem of a large mission critical system with a nationwide deployment based on NServiceBus. It was impressive to see how he took the initial architecture and turned it upside down leading to a very flexible and scalable yet simple system without knowing the details of the business domain.
I highly recommend consulting with Udi when it comes to large scale mission critical systems in any domain.”
 Simon Segal, Independent Consultant
Simon Segal, Independent Consultant
“Udi is one of the outstanding software development minds in the world today, his vast insights into Service Oriented Architectures and Smart Clients in particular are indeed a rare commodity. Udi is also an exceptional teacher and can help lead teams to fall into the pit of success. I would recommend Udi to anyone considering some Architecural guidance and support in their next project.”
 Ohad Israeli, Chief Architect at Hewlett-Packard, Indigo Division
Ohad Israeli, Chief Architect at Hewlett-Packard, Indigo Division
“When you need a man to do the job Udi is your man! No matter if you are facing near deadline deadlock or at the early stages of your development, if you have a problem Udi is the one who will probably be able to solve it, with his large experience at the industry and his widely horizons of thinking , he is always full of just in place great architectural ideas.
I am honored to have Udi as a colleague and a friend (plus having his cell phone on my speed dial).”
 Ward Bell, VP Product Development at IdeaBlade
Ward Bell, VP Product Development at IdeaBlade
“Everyone will tell you how smart and knowledgable Udi is ... and they are oh-so-right. Let me add that Udi is a smart LISTENER. He's always calibrating what he has to offer with your needs and your experience ... looking for the fit. He has strongly held views ... and the ability to temper them with the nuances of the situation. I trust Udi to tell me what I need to hear, even if I don't want to hear it, ... in a way that I can hear it. That's a rare skill to go along with his command and intelligence.”
Eli Brin, Program Manager at RISCO Group
“We hired Udi as a SOA specialist for a large scale project. The development is outsourced to India. SOA is a buzzword used almost for anything today. We wanted to understand what SOA really is, and what is the meaning and practice to develop a SOA based system.
We identified Udi as the one that can put some sense and order in our minds. We started with a private customized SOA training for the entire team in Israel. After that I had several focused sessions regarding our architecture and design.
I will summarize it simply (as he is the software simplist): We are very happy to have Udi in our project. It has a great benefit. We feel good and assured with the knowledge and practice he brings. He doesn’t talk over our heads. We assimilated nServicebus as the ESB of the project. I highly recommend you to bring Udi into your project.”
 Catherine Hole, Senior Project Manager at the Norwegian Health Network
Catherine Hole, Senior Project Manager at the Norwegian Health Network
“My colleagues and I have spent five interesting days with Udi - diving into the many aspects of SOA. Udi has shown impressive abilities of understanding organizational challenges, and has brought the business perspective into our way of looking at services. He has an excellent understanding of the many layers from business at the top to the technical infrstructure at the bottom. He is a great listener, and manages to simplify challenges in a way that is understandable both for developers and CEOs, and all the specialists in between.”
 Yoel Arnon, MSMQ Expert
Yoel Arnon, MSMQ Expert
“Udi has a unique, in depth understanding of service oriented architecture and how it should be used in the real world, combined with excellent presentation skills. I think Udi should be a premier choice for a consultant or architect of distributed systems.”
Vadim Mesonzhnik, Development Project Lead at Polycom
“When we were faced with a task of creating a high performance server for a video-tele conferencing domain we decided to opt for a stateless cluster with SQL server approach. In order to confirm our decision we invited Udi.
After carefully listening for 2 hours he said: "With your kind of high availability and performance requirements you don’t want to go with stateless architecture."
One simple sentence saved us from implementing a wrong product and finding that out after years of development. No matter whether our former decisions were confirmed or altered, it gave us great confidence to move forward relying on the experience, industry best-practices and time-proven techniques that Udi shared with us.
It was a distinct pleasure and a unique opportunity to learn from someone who is among the best at what he does.”
 Jack Van Hoof, Enterprise Integration Architect at Dutch Railways
Jack Van Hoof, Enterprise Integration Architect at Dutch Railways
“Udi is a respected visionary on SOA and EDA, whose opinion I most of the time (if not always) highly agree with. The nice thing about Udi is that he is able to explain architectural concepts in terms of practical code-level examples.”
 Neil Robbins, Applications Architect at Brit Insurance
Neil Robbins, Applications Architect at Brit Insurance
“Having followed Udi's blog and other writings for a number of years I attended Udi's two day course on 'Loosely Coupled Messaging with NServiceBus' at SkillsMatter, London.
I would strongly recommend this course to anyone with an interest in how to develop IT systems which provide immediate and future fitness for purpose. An influential and innovative thought leader and practitioner in his field, Udi demonstrates and shares a phenomenally in depth knowledge that proves his position as one of the premier experts in his field globally.
The course has enhanced my knowledge and skills in ways that I am able to immediately apply to provide benefits to my employer. Additionally though I will be able to build upon what I learned in my 2 days with Udi and have no doubt that it will only enhance my future career.
I cannot recommend Udi, and his courses, highly enough.”
 Nick Malik, Enterprise Architect at Microsoft Corporation
Nick Malik, Enterprise Architect at Microsoft Corporation
“ You are an excellent speaker and trainer, Udi, and I've had the fortunate experience of having attended one of your presentations. I believe that you are a knowledgable and intelligent man.”
 Sean Farmar, Chief Technical Architect at Candidate Manager Ltd
Sean Farmar, Chief Technical Architect at Candidate Manager Ltd
“Udi has provided us with guidance in system architecture and supports our implementation of NServiceBus in our core business application.
He accompanied us in all stages of our development cycle and helped us put vision into real life distributed scalable software. He brought fresh thinking, great in depth of understanding software, and ongoing support that proved as valuable and cost effective.
Udi has the unique ability to analyze the business problem and come up with a simple and elegant solution for the code and the business alike. With Udi's attention to details, and knowledge we avoided pit falls that would cost us dearly.”
 Børge Hansen, Architect Advisor at Microsoft
Børge Hansen, Architect Advisor at Microsoft
“Udi delivered a 5 hour long workshop on SOA for aspiring architects in Norway. While keeping everyone awake and excited Udi gave us some great insights and really delivered on making complex software challenges simple. Truly the software simplist.”
Motty Cohen, SW Manager at KorenTec Technologies
“I know Udi very well from our mutual work at KorenTec. During the analysis and design of a complex, distributed C4I system - where the basic concepts of NServiceBus start to emerge - I gained a lot of "Udi's hours" so I can surely say that he is a professional, skilled architect with fresh ideas and unique perspective for solving complex architecture challenges. His ideas, concepts and parts of the artifacts are the basis of several state-of-the-art C4I systems that I was involved in their architecture design.”
 Aaron Jensen, VP of Engineering at Eleutian Technology
Aaron Jensen, VP of Engineering at Eleutian Technology
“ Awesome. Just awesome.
We’d been meaning to delve into messaging at Eleutian after multiple discussions with and blog posts from Greg Young and Udi Dahan in the past. We weren’t entirely sure where to start, how to start, what tools to use, how to use them, etc. Being able to sit in a room with Udi for an entire week while he described exactly how, why and what he does to tackle a massive enterprise system was invaluable to say the least.
We now have a much better direction and, more importantly, have the confidence we need to start introducing these powerful concepts into production at Eleutian.”
 Gad Rosenthal, Department Manager at Retalix
Gad Rosenthal, Department Manager at Retalix
“A thinking person. Brought fresh and valuable ideas that helped us in architecting our product. When recommending a solution he supports it with evidence and detail so you can successfully act based on it. Udi's support "comes on all levels" - As the solution architect through to the detailed class design. Trustworthy!”
 Chris Bilson, Developer at Russell Investment Group
Chris Bilson, Developer at Russell Investment Group
“I had the pleasure of attending a workshop Udi led at the Seattle ALT.NET conference in February 2009. I have been reading Udi's articles and listening to his podcasts for a long time and have always looked to him as a source of advice on software architecture. When I actually met him and talked to him I was even more impressed. Not only is Udi an extremely likable person, he's got that rare gift of being able to explain complex concepts and ideas in a way that is easy to understand. All the attendees of the workshop greatly appreciate the time he spent with us and the amazing insights into service oriented architecture he shared with us.”
 Alexey Shestialtynov, Senior .Net Developer at Candidate Manager
Alexey Shestialtynov, Senior .Net Developer at Candidate Manager
“I met Udi at Candidate Manager where he was brought in part-time as a consultant to help the company make its flagship product more scalable. For me, even after 30 years in software development, working with Udi was a great learning experience. I simply love his fresh ideas and architecture insights. As we all know it is not enough to be armed with best tools and technologies to be successful in software - there is still human factor involved. When, as it happens, the project got in trouble, management asked Udi to step into a leadership role and bring it back on track. This he did in the span of a month. I can only wish that things had been done this way from the very beginning. I look forward to working with Udi again in the future.”
 Christopher Bennage, President at Blue Spire Consulting, Inc.
Christopher Bennage, President at Blue Spire Consulting, Inc.
“My company was hired to be the primary development team for a large scale and highly distributed application. Since these are not necessarily everyday requirements, we wanted to bring in some additional expertise. We chose Udi because of his blogging, podcasting, and speaking. We asked him to to review our architectural strategy as well as the overall viability of project.
I was very impressed, as Udi demonstrated a broad understanding of the sorts of problems we would face. His advice was honest and unbiased and very pragmatic. Whenever I questioned him on particular points, he was able to backup his opinion with real life examples.
I was also impressed with his clarity and precision. He was very careful to untangle the meaning of words that might be overloaded or otherwise confusing. While Udi's hourly rate may not be the cheapest, the ROI is undoubtedly a deal.
I would highly recommend consulting with Udi.”
Robert Lewkovich, Product / Development Manager at Eggs Overnight
“Udi's advice and consulting were a huge time saver for the project I'm responsible for. The $ spent were well worth it and provided me with a more complete understanding of nServiceBus and most importantly in helping make the correct architectural decisions earlier thereby reducing later, and more expensive, rework.”
 Ray Houston, Director of Development at TOPAZ Technologies
Ray Houston, Director of Development at TOPAZ Technologies
“Udi's SOA class made me smart - it was awesome.
The class was very well put together. The materials were clear and concise and Udi did a fantastic job presenting it. It was a good mixture of lecture, coding, and question and answer. I fully expected that I would be taking notes like crazy, but it was so well laid out that the only thing I wrote down the entire course was what I wanted for lunch. Udi provided us with all the lecture materials and everyone has access to all of the samples which are in the nServiceBus trunk.
Now I know why Udi is the "Software Simplist." I was amazed to find that all the code and solutions were indeed very simple. The patterns that Udi presented keep things simple by isolating complexity so that it doesn't creep into your day to day code. The domain code looks the same if it's running in a single process or if it's running in 100 processes.”
 Ian Cooper, Team Lead at Beazley
Ian Cooper, Team Lead at Beazley
“Udi is one of the leaders in the .Net development community, one of the truly smart guys who do not just get best architectural practice well enough to educate others but drives innovation. Udi consistently challenges my thinking in ways that make me better at what I do.”
Liron Levy, Team Leader at Rafael
“I've met Udi when I worked as a team leader in Rafael. One of the most senior managers there knew Udi because he was doing superb architecture job in another Rafael project and he recommended bringing him on board to help the project I was leading. Udi brought with him fresh solutions and invaluable deep architecture insights. He is an authority on SOA (service oriented architecture) and this was a tremendous help in our project. On the personal level - Udi is a great communicator and can persuade even the most difficult audiences (I was part of such an audience myself..) by bringing sound explanations that draw on his extensive knowledge in the software business. Working with Udi was a great learning experience for me, and I'll be happy to work with him again in the future.”
 Adam Dymitruk, Director of IT at Apara Systems
Adam Dymitruk, Director of IT at Apara Systems
“I met Udi for the first time at DevTeach in Montreal back in early 2007. While Udi is usually involved in SOA subjects, his knowledge spans all of a software development company's concerns. I would not hesitate to recommend Udi for any company that needs excellent leadership, mentoring, problem solving, application of patterns, implementation of methodologies and straight out solution development. There are very few people in the world that are as dedicated to their craft as Udi is to his. At ALT.NET Seattle, Udi explained many core ideas about SOA. The team that I brought with me found his workshop and other talks the highlight of the event and provided the most value to us and our organization. I am thrilled to have the opportunity to recommend him.”
 Eytan Michaeli, CTO Korentec
Eytan Michaeli, CTO Korentec
“Udi was responsible for a major project in the company, and as a chief architect designed a complex multi server C4I system with many innovations and excellent performance.”
 Carl Kenne, .Net Consultant at Dotway AB
Carl Kenne, .Net Consultant at Dotway AB
“Udi's session "DDD in Enterprise apps" was truly an eye opener. Udi has a great ability to explain complex enterprise designs in a very comprehensive and inspiring way. I've seen several sessions on both DDD and SOA in the past, but Udi puts it in a completly new perspective and makes us understand what it's all really about. If you ever have a chance to see any of Udi's sessions in the future, take it!”
Avi Nehama, R&D Project Manager at Retalix
“Not only that Udi is a briliant software architecture consultant, he also has remarkable abilities to present complex ideas in a simple and concise manner, and...
always with a smile. Udi is indeed a top-league professional!”
 Ben Scheirman, Lead Developer at CenterPoint Energy
Ben Scheirman, Lead Developer at CenterPoint Energy
“Udi is one of those rare people who not only deeply understands SOA and domain driven design, but also eloquently conveys that in an easy to grasp way. He is patient, polite, and easy to talk to. I'm extremely glad I came to his workshop on SOA.”
 Scott C. Reynolds, Director of Software Engineering at CBLPath
Scott C. Reynolds, Director of Software Engineering at CBLPath
“Udi is consistently advancing the state of thought in software architecture, service orientation, and domain modeling.
His mastery of the technologies and techniques is second to none, but he pairs that with a singular ability to listen and communicate effectively with all parties, technical and non, to help people arrive at context-appropriate solutions.
Every time I have worked with Udi, or attended a talk of his, or just had a conversation with him I have come away from it enriched with new understanding about the ideas discussed.”
Evgeny-Hen Osipow, Head of R&D at PCLine
“Udi has helped PCLine on projects by implementing architectural blueprints demonstrating the value of simple design and code.”
 Rhys Campbell, Owner at Artemis West
Rhys Campbell, Owner at Artemis West
“For many years I have been following the works of Udi. His explanation of often complex design and architectural concepts are so cleanly broken down that even the most junior of architects can begin to understand these concepts. These concepts however tend to typify the "real world" problems we face daily so even the most experienced software expert will find himself in an "Aha!" moment when following Udi teachings.
It was a pleasure to finally meet Udi in Seattle Alt.Net OpenSpaces 2008, where I was pleasantly surprised at how down-to-earth and approachable he was. His depth and breadth of software knowledge also became apparent when discussion with his peers quickly dove deep in to the problems we current face. If given the opportunity to work with or recommend Udi I would quickly take that chance. When I think .Net Architecture, I think Udi.”
 Sverre Hundeide, Senior Consultant at Objectware
Sverre Hundeide, Senior Consultant at Objectware
“Udi had been hired to present the third LEAP master class in Oslo. He is an well known international expert on enterprise software architecture and design, and is the author of the open source messaging framework nServiceBus.
The entire class was based on discussion and interaction with the audience, and the only Power Point slide used was the one showing the agenda.
He started out with sketching a naive traditional n-tier application (big ball of mud), and based on suggestions from the audience we explored different solutions which might improve the solution. Whatever suggestions we threw at him, he always had a thoroughly considered answer describing pros and cons with the suggested solution. He obviously has a lot of experience with real world enterprise SOA applications.”
 Raphaël Wouters, Owner/Managing Partner at Medinternals
Raphaël Wouters, Owner/Managing Partner at Medinternals
“I attended Udi's excellent course 'Advanced Distributed System Design with SOA and DDD' at Skillsmatter. Few people can truly claim such a high skill and expertise level, present it using a pragmatic, concrete no-nonsense approach and still stay reachable.”
 Nimrod Peleg, Lab Engineer at Technion IIT
Nimrod Peleg, Lab Engineer at Technion IIT
“One of the best programmers and software engineer I've ever met, creative, knows how to design and implemet, very collaborative and finally - the applications he designed implemeted work for many years without any problems!”
Jose Manuel Beas
“When I attended Udi's SOA Workshop, then it suddenly changed my view of what Service Oriented Architectures were all about. Udi explained complex concepts very clearly and created a very productive discussion environment where all the attendees could learn a lot. I strongly recommend hiring Udi.”
 Daniel Jin, Senior Lead Developer at PJM Interconnection
Daniel Jin, Senior Lead Developer at PJM Interconnection
“Udi is one of the top SOA guru in the .NET space. He is always eager to help others by sharing his knowledge and experiences. His blog articles often offer deep insights and is a invaluable resource. I highly recommend him.”
 Pasi Taive, Chief Architect at Tieto
Pasi Taive, Chief Architect at Tieto
“I attended both of Udi's "UI Composition Key to SOA Success" and "DDD in Enterprise Apps" sessions and they were exceptionally good. I will definitely participate in his sessions again. Udi is a great presenter and has the ability to explain complex issues in a manner that everyone understands.”
Eran Sagi, Software Architect at HP
“So far, I heard about Service Oriented architecture all over.
Everyone mentions it – the big buzz word.
But, when I actually asked someone for what does it really mean, no one managed to give me a complete satisfied answer.
Finally in his excellent course “Advanced Distributed Systems”, I got the answers I was looking for.
Udi went over the different motivations (principles) of Services Oriented, explained them well one by one, and showed how each one could be technically addressed using NService bus.
In his course, Udi also explain the way of thinking when coming to design a Service Oriented system.
What are the questions you need to ask yourself in order to shape your system, place the logic in the right places for best Service Oriented system.
I would recommend this course for any architect or developer who deals with distributed system, but not only.
In my work we do not have a real distributed system, but one PC which host both the UI application and the different services inside, all communicating via WCF.
I found that many of the architecture principles and motivations of SOA apply for our system as well. Enough that you have SW partitioned into components and most of the principles becomes relevant to you as well.
Bottom line – an excellent course recommended to any SW Architect, or any developer dealing with distributed system.”
Consult with Udi
Guest Authored Books
|







{kind=link}