Bryan Wheeler, Director Platform Development at msnbc.com
“
Udi Dahan is the real deal.We brought him on site to give our development staff the 5-day “Advanced Distributed System Design” training. The course profoundly changed our understanding and approach to SOA and distributed systems.
Consider some of the evidence: 1. Months later, developers still make allusions to concepts learned in the course nearly every day 2. One of our developers went home and made her husband (a developer at another company) sign up for the course at a subsequent date/venue 3. Based on what we learned, we’ve made constant improvements to our architecture that have helped us to adapt to our ever changing business domain at scale and speed If you have the opportunity to receive the training, you will make a substantial paradigm shift.
If I were to do the whole thing over again, I’d start the week by playing the clip from the Matrix where Morpheus offers Neo the choice between the red and blue pills. Once you make the intellectual leap, you’ll never look at distributed systems the same way.
Beyond the training, we were able to spend some time with Udi discussing issues unique to our business domain. Because Udi is a rare combination of a big picture thinker and a low level doer, he can quickly hone in on various issues and quickly make good (if not startling) recommendations to help solve tough technical issues.” November 11, 2010
 Sam Gentile, Independent WCF & SOA Expert
Sam Gentile, Independent WCF & SOA Expert
“Udi, one of the great minds in this area.
A man I respect immensely.”
 Ian Robinson, Principal Consultant at ThoughtWorks
Ian Robinson, Principal Consultant at ThoughtWorks
"Your blog and articles have been enormously useful in shaping, testing and refining my own approach to delivering on SOA initiatives over the last few years. Over and against a certain 3-layer-application-architecture-blown-out-to- distributed-proportions school of SOA,
your writing, steers a far more valuable course."
 Shy Cohen, Senior Program Manager at Microsoft
Shy Cohen, Senior Program Manager at Microsoft
“Udi is a world renowned software architect and speaker. I met Udi at a conference that we were both speaking at, and immediately recognized his keen insight and razor-sharp intellect. Our shared passion for SOA and the advancement of its practice launched a discussion that lasted into the small hours of the night.
It was evident through that discussion that Udi is one of the most knowledgeable people in the SOA space. It was also clear why – Udi does not settle for mediocrity, and seeks to fully understand (or define) the logic and principles behind things.
Humble yet uncompromising, Udi is a pleasure to interact with.”
 Glenn Block, Senior Program Manager - WCF at Microsoft
Glenn Block, Senior Program Manager - WCF at Microsoft
“I have known Udi for many years having attended his workshops and having several personal interactions including working with him when we were building our Composite Application Guidance in patterns & practices.
What impresses me about Udi is his deep insight into how to address business problems through sound architecture. Backed by many years of building mission critical real world distributed systems it is no wonder that Udi is the best at what he does. When customers have deep issues with their system design, I point them Udi's way.”
 Karl Wannenmacher, Senior Lead Expert at Frequentis AG
Karl Wannenmacher, Senior Lead Expert at Frequentis AG
“I have been following Udi’s blog and podcasts since 2007. I’m convinced that he is one of the most knowledgeable and experienced people in the field of SOA, EDA and large scale systems.
Udi helped Frequentis to design a major subsystem of a large mission critical system with a
nationwide deployment based on NServiceBus. It was impressive to see how he took the initial architecture and turned it upside down leading to a very flexible and scalable yet simple system without knowing the details of the business domain.
I highly recommend consulting with Udi when it comes to large scale mission critical systems in any domain.”
 Simon Segal, Independent Consultant
Simon Segal, Independent Consultant
“Udi is one of the outstanding software development minds in the world today, his vast insights into Service Oriented Architectures and Smart Clients in particular are indeed a rare commodity.
Udi is also an exceptional teacher and can help lead teams to fall into the pit of success. I would recommend Udi to anyone considering some Architecural guidance and support in their next project.”
 Ohad Israeli, Chief Architect at Hewlett-Packard, Indigo Division
Ohad Israeli, Chief Architect at Hewlett-Packard, Indigo Division
“When you need a man to do the job Udi is your man! No matter if you are facing near deadline deadlock or at the early stages of your development, if you have a problem Udi is the one who will probably be able to solve it, with his large experience at the industry and his widely horizons of thinking , he is always
full of just in place great architectural ideas.
I am honored to have Udi as a colleague and a friend (plus having his cell phone on my speed dial).”
 Ward Bell, VP Product Development at IdeaBlade
Ward Bell, VP Product Development at IdeaBlade
“Everyone will tell you how smart and knowledgable Udi is ... and they are oh-so-right. Let me add that Udi is a smart LISTENER. He's always calibrating what he has to offer with your needs and your experience ... looking for the fit. He has strongly held views ... and the ability to temper them with the nuances of the situation.
I trust Udi to tell me what I need to hear, even if I don't want to hear it, ... in a way that I can hear it. That's a rare skill to go along with his command and intelligence.”
Eli Brin, Program Manager at RISCO Group
“We hired Udi as a SOA specialist for a large scale project. The development is outsourced to India. SOA is a buzzword used almost for anything today. We wanted to understand what SOA really is, and what is the meaning and practice to develop a SOA based system.
We identified Udi as the one that can put some sense and order in our minds. We started with a private customized SOA training for the entire team in Israel. After that I had several focused sessions regarding our architecture and design.
I will summarize it simply (as he is the software simplist): We are very happy to have Udi in our project. It has a great benefit. We feel good and assured with the knowledge and practice he brings.
He doesn’t talk over our heads. We assimilated nServicebus as the ESB of the project. I highly recommend you to bring Udi into your project.”
 Catherine Hole, Senior Project Manager at the Norwegian Health Network
Catherine Hole, Senior Project Manager at the Norwegian Health Network
“My colleagues and I have spent five interesting days with Udi - diving into the many aspects of SOA. Udi has shown impressive abilities of understanding organizational challenges, and has brought the business perspective into our way of looking at services. He has an excellent understanding of the many layers from business at the top to the technical infrstructure at the bottom. He is a great listener, and manages to simplify challenges in a way that is
understandable both for developers and CEOs, and all the specialists in between.”
 Yoel Arnon, MSMQ Expert
Yoel Arnon, MSMQ Expert
“Udi has a unique, in depth understanding of service oriented architecture and
how it should be used in the real world, combined with excellent presentation skills. I think Udi should be a premier choice for a consultant or architect of distributed systems.”
Vadim Mesonzhnik, Development Project Lead at Polycom
“When we were faced with a task of creating a high performance server for a video-tele conferencing domain we decided to opt for a stateless cluster with SQL server approach. In order to confirm our decision we invited Udi.
After carefully listening for 2 hours he said: "With your kind of high availability and performance requirements you don’t want to go with stateless architecture."
One simple sentence saved us from implementing a wrong product and finding that out after years of development. No matter whether our former decisions were confirmed or altered, it gave us great confidence to move forward relying on the experience, industry best-practices and time-proven techniques that Udi shared with us.
It was a distinct pleasure and a unique opportunity to learn from someone who is among the best at what he does.”
 Jack Van Hoof, Enterprise Integration Architect at Dutch Railways
Jack Van Hoof, Enterprise Integration Architect at Dutch Railways
“Udi is a respected visionary on SOA and EDA, whose opinion I most of the time (if not always) highly agree with.
The nice thing about Udi is that he is able to explain architectural concepts in terms of practical code-level examples.”
 Neil Robbins, Applications Architect at Brit Insurance
Neil Robbins, Applications Architect at Brit Insurance
“Having followed Udi's blog and other writings for a number of years I attended Udi's two day course on 'Loosely Coupled Messaging with NServiceBus' at SkillsMatter, London.
I would strongly recommend this course to anyone with an interest in how to develop IT systems which provide immediate and future fitness for purpose. An influential and innovative thought leader and practitioner in his field, Udi demonstrates and shares a phenomenally in depth knowledge that proves his position as one of the premier experts in his field globally.
The course has enhanced my knowledge and skills in ways that I am able to immediately apply to provide benefits to my employer. Additionally though I will be able to build upon what I learned in my 2 days with Udi and have no doubt that it will only enhance my future career.
I cannot recommend Udi, and his courses, highly enough.”
 Nick Malik, Enterprise Architect at Microsoft Corporation
Nick Malik, Enterprise Architect at Microsoft Corporation
“
You are an excellent speaker and trainer, Udi, and I've had the fortunate experience of having attended one of your presentations. I believe that you are a knowledgable and intelligent man.”
 Sean Farmar, Chief Technical Architect at Candidate Manager Ltd
Sean Farmar, Chief Technical Architect at Candidate Manager Ltd
“Udi has provided us with guidance in system architecture and supports our implementation of NServiceBus in our core business application.
He accompanied us in all stages of our development cycle and helped us put vision into real life distributed scalable software. He brought fresh thinking, great in depth of understanding software, and ongoing support that proved as valuable and cost effective.
Udi has the unique ability to analyze the business problem and come up with a simple and elegant solution for the code and the business alike.
With Udi's attention to details, and knowledge we avoided pit falls that would cost us dearly.”
 Børge Hansen, Architect Advisor at Microsoft
Børge Hansen, Architect Advisor at Microsoft
“Udi delivered a 5 hour long workshop on SOA for aspiring architects in Norway. While
keeping everyone awake and excited Udi gave us some great insights and really delivered on making complex software challenges simple. Truly the software simplist.”
Motty Cohen, SW Manager at KorenTec Technologies
“I know Udi very well from our mutual work at KorenTec. During the analysis and design of a complex, distributed C4I system - where the basic concepts of NServiceBus start to emerge - I gained a lot of "Udi's hours" so I can surely say that he is a professional, skilled architect with
fresh ideas and unique perspective for solving complex architecture challenges. His ideas, concepts and parts of the artifacts are the basis of several state-of-the-art C4I systems that I was involved in their architecture design.”
 Aaron Jensen, VP of Engineering at Eleutian Technology
Aaron Jensen, VP of Engineering at Eleutian Technology
“
Awesome. Just awesome.
We’d been meaning to delve into messaging at Eleutian after multiple discussions with and blog posts from Greg Young and Udi Dahan in the past. We weren’t entirely sure where to start, how to start, what tools to use, how to use them, etc. Being able to sit in a room with Udi for an entire week while he described exactly how, why and what he does to tackle a massive enterprise system was invaluable to say the least.
We now have a much better direction and, more importantly, have the confidence we need to start introducing these powerful concepts into production at Eleutian.”
 Gad Rosenthal, Department Manager at Retalix
Gad Rosenthal, Department Manager at Retalix
“A thinking person. Brought fresh and valuable ideas that helped us in architecting our product.
When recommending a solution he supports it with evidence and detail so you can successfully act based on it. Udi's support "comes on all levels" - As the solution architect through to the detailed class design. Trustworthy!”
 Chris Bilson, Developer at Russell Investment Group
Chris Bilson, Developer at Russell Investment Group
“I had the pleasure of attending a workshop Udi led at the Seattle ALT.NET conference in February 2009. I have been reading Udi's articles and listening to his podcasts for a long time and have always looked to him as a source of advice on software architecture.
When I actually met him and talked to him I was even more impressed.
Not only is Udi an extremely likable person, he's got that rare gift of being able to explain complex concepts and ideas in a way that is easy to understand.
All the attendees of the workshop greatly appreciate the time he spent with us and the amazing insights into service oriented architecture he shared with us.”
 Alexey Shestialtynov, Senior .Net Developer at Candidate Manager
Alexey Shestialtynov, Senior .Net Developer at Candidate Manager
“I met Udi at Candidate Manager where he was brought in part-time as a consultant to help the company make its flagship product more scalable. For me, even after 30 years in software development,
working with Udi was a great learning experience. I simply love his fresh ideas and architecture insights.
As we all know it is not enough to be armed with best tools and technologies to be successful in software - there is still human factor involved. When, as it happens, the project got in trouble, management asked Udi to step into a leadership role and bring it back on track. This he did in the span of a month. I can only wish that things had been done this way from the very beginning.
I look forward to working with Udi again in the future.”
 Christopher Bennage, President at Blue Spire Consulting, Inc.
Christopher Bennage, President at Blue Spire Consulting, Inc.
“My company was hired to be the primary development team for a large scale and highly distributed application. Since these are not necessarily everyday requirements, we wanted to bring in some additional expertise. We chose Udi because of his blogging, podcasting, and speaking. We asked him to to review our architectural strategy as well as the overall viability of project.
I was very impressed, as Udi demonstrated a broad understanding of the sorts of problems we would face. His advice was honest and unbiased and very pragmatic. Whenever I questioned him on particular points, he was able to backup his opinion with real life examples.
I was also impressed with his clarity and precision. He was very careful to untangle the meaning of words that might be overloaded or otherwise confusing. While Udi's hourly rate may not be the cheapest,
the ROI is undoubtedly a deal.
I would highly recommend consulting with Udi.”
Robert Lewkovich, Product / Development Manager at Eggs Overnight
“Udi's advice and consulting were a huge time saver for the project I'm responsible for.
The $ spent were well worth it and provided me with a more complete understanding of nServiceBus and most importantly in helping make the correct architectural decisions earlier thereby reducing later, and more expensive, rework.”
 Ray Houston, Director of Development at TOPAZ Technologies
Ray Houston, Director of Development at TOPAZ Technologies
“Udi's SOA class made me smart - it was awesome.
The class was very well put together. The materials were clear and concise and Udi did a fantastic job presenting it. It was a good mixture of lecture, coding, and question and answer. I fully expected that I would be taking notes like crazy, but it was so well laid out that the only thing I wrote down the entire course was what I wanted for lunch. Udi provided us with all the lecture materials and everyone has access to all of the samples which are in the nServiceBus trunk.
Now I know why Udi is the "Software Simplist." I was amazed to find that all the code and solutions were indeed very simple. The patterns that Udi presented keep things simple by isolating complexity so that it doesn't creep into your day to day code. The domain code looks the same if it's running in a single process or if it's running in 100 processes.”
 Ian Cooper, Team Lead at Beazley
Ian Cooper, Team Lead at Beazley
“Udi is one of the leaders in the .Net development community, one of the truly smart guys who do not just get best architectural practice well enough to educate others but drives innovation. Udi consistently challenges my thinking in ways that
make me better at what I do.”
Liron Levy, Team Leader at Rafael
“I've met Udi when I worked as a team leader in Rafael. One of the most senior managers there knew Udi because he was doing superb architecture job in another Rafael project and he recommended bringing him on board to help the project I was leading.
Udi brought with him fresh solutions and invaluable deep architecture insights. He is an authority on SOA (service oriented architecture) and this was a tremendous help in our project.
On the personal level -
Udi is a great communicator and can persuade even the most difficult audiences (I was part of such an audience myself..) by bringing sound explanations that draw on his extensive knowledge in the software business. Working with Udi was a great learning experience for me, and I'll be happy to work with him again in the future.”
 Adam Dymitruk, Director of IT at Apara Systems
Adam Dymitruk, Director of IT at Apara Systems
“I met Udi for the first time at DevTeach in Montreal back in early 2007. While Udi is usually involved in SOA subjects,
his knowledge spans all of a software development company's concerns. I would not hesitate to recommend Udi for any company that needs excellent leadership, mentoring, problem solving, application of patterns, implementation of methodologies and straight out solution development.
There are very few people in the world that are as dedicated to their craft as Udi is to his. At ALT.NET Seattle, Udi explained many core ideas about SOA. The team that I brought with me found his workshop and other talks the highlight of the event and provided the most value to us and our organization. I am thrilled to have the opportunity to recommend him.”
 Eytan Michaeli, CTO Korentec
Eytan Michaeli, CTO Korentec
“Udi was responsible for a major project in the company, and as a chief architect designed a complex multi server C4I system with many innovations and excellent performance.”
 Carl Kenne, .Net Consultant at Dotway AB
Carl Kenne, .Net Consultant at Dotway AB
“Udi's session "DDD in Enterprise apps" was truly an eye opener. Udi has a great ability to explain complex enterprise designs in a very comprehensive and inspiring way. I've seen several sessions on both DDD and SOA in the past, but Udi puts it in a completly new perspective and
makes us understand what it's all really about. If you ever have a chance to see any of Udi's sessions in the future, take it!”
Avi Nehama, R&D Project Manager at Retalix
“Not only that Udi is a briliant software architecture consultant, he also has remarkable abilities to present complex ideas in a simple and concise manner, and...
always with a smile. Udi is indeed a top-league professional!”
 Ben Scheirman, Lead Developer at CenterPoint Energy
Ben Scheirman, Lead Developer at CenterPoint Energy
“Udi is one of those rare people who not only deeply understands SOA and domain driven design, but also eloquently conveys that in an easy to grasp way.
He is patient, polite, and easy to talk to. I'm extremely glad I came to his workshop on SOA.”
 Scott C. Reynolds, Director of Software Engineering at CBLPath
Scott C. Reynolds, Director of Software Engineering at CBLPath
“Udi is consistently advancing the state of thought in software architecture, service orientation, and domain modeling.
His mastery of the technologies and techniques is second to none, but he pairs that with a singular ability to listen and communicate effectively with all parties, technical and non, to help people
arrive at context-appropriate solutions.
Every time I have worked with Udi, or attended a talk of his, or just had a conversation with him I have come away from it enriched with new understanding about the ideas discussed.”
Evgeny-Hen Osipow, Head of R&D at PCLine
“Udi has helped PCLine on projects by implementing architectural blueprints demonstrating the value of simple design and code.”
 Rhys Campbell, Owner at Artemis West
Rhys Campbell, Owner at Artemis West
“For many years I have been following the works of Udi. His explanation of often complex design and architectural concepts are so cleanly broken down that even the most junior of architects can begin to understand these concepts. These concepts however tend to typify the "real world" problems we face daily so even the most experienced software expert will find himself in an "Aha!" moment when following Udi teachings.
It was a pleasure to finally meet Udi in Seattle Alt.Net OpenSpaces 2008, where I was pleasantly surprised at
how down-to-earth and approachable he was. His depth and breadth of software knowledge also became apparent when discussion with his peers quickly dove deep in to the problems we current face. If given the opportunity to work with or recommend Udi I would quickly take that chance. When I think .Net Architecture, I think Udi.”
 Sverre Hundeide, Senior Consultant at Objectware
Sverre Hundeide, Senior Consultant at Objectware
“Udi had been hired to present the third LEAP master class in Oslo. He is an well known international expert on enterprise software architecture and design, and is the author of the open source messaging framework nServiceBus.
The entire class was based on discussion and interaction with the audience, and the only Power Point slide used was the one showing the agenda.
He started out with sketching a naive traditional n-tier application (big ball of mud), and based on suggestions from the audience we explored different solutions which might improve the solution. Whatever suggestions we threw at him, he always had a thoroughly considered answer describing pros and cons with the suggested solution.
He obviously has a lot of experience with real world enterprise SOA applications.”
 Raphaël Wouters, Owner/Managing Partner at Medinternals
Raphaël Wouters, Owner/Managing Partner at Medinternals
“I attended Udi's excellent course 'Advanced Distributed System Design with SOA and DDD' at Skillsmatter. Few people can truly claim such a high skill and expertise level, present it using a
pragmatic, concrete no-nonsense approach and still stay reachable.”
 Nimrod Peleg, Lab Engineer at Technion IIT
Nimrod Peleg, Lab Engineer at Technion IIT
“One of the best programmers and software engineer I've ever met, creative, knows how to design and implemet, very collaborative and finally -
the applications he designed implemeted work for many years without any problems!”
Jose Manuel Beas
“When I attended Udi's SOA Workshop, then it suddenly changed my view of what Service Oriented Architectures were all about. Udi explained complex concepts very clearly and created a very productive discussion environment
where all the attendees could learn a lot. I strongly recommend hiring Udi.”
 Daniel Jin, Senior Lead Developer at PJM Interconnection
Daniel Jin, Senior Lead Developer at PJM Interconnection
“Udi is one of the top SOA guru in the .NET space. He is always
eager to help others by sharing his knowledge and experiences. His blog articles often offer deep insights and is a invaluable resource. I highly recommend him.”
 Pasi Taive, Chief Architect at Tieto
Pasi Taive, Chief Architect at Tieto
“I attended both of Udi's "UI Composition Key to SOA Success" and "DDD in Enterprise Apps" sessions and they were exceptionally good. I will definitely participate in his sessions again.
Udi is a great presenter and has the ability to explain complex issues in a manner that everyone understands.”
Eran Sagi, Software Architect at HP
“So far, I heard about Service Oriented architecture all over.
Everyone mentions it – the big buzz word.
But, when I actually asked someone for what does it really mean, no one managed to give me a complete satisfied answer.
Finally in his excellent course “Advanced Distributed Systems”,
I got the answers I was looking for.
Udi went over the different motivations (principles) of Services Oriented, explained them well one by one, and showed how each one could be technically addressed using NService bus.
In his course, Udi also explain the way of thinking when coming to design a Service Oriented system.
What are the questions you need to ask yourself in order to shape your system, place the logic in the right places for best Service Oriented system.
I would recommend this course for any architect or developer who deals with distributed system, but not only.
In my work we do not have a real distributed system, but one PC which host both the UI application and the different services inside, all communicating via WCF.
I found that many of the architecture principles and motivations of SOA apply for our system as well. Enough that you have SW partitioned into components and most of the principles becomes relevant to you as well.
Bottom line – an excellent course recommended to any SW Architect, or any developer dealing with distributed system.”
Consult with Udi

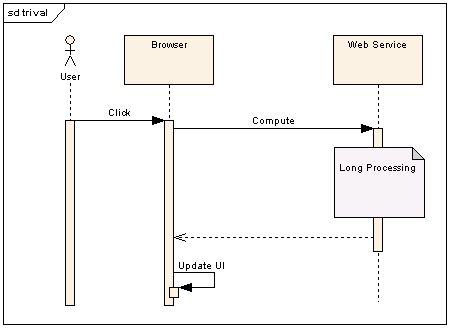
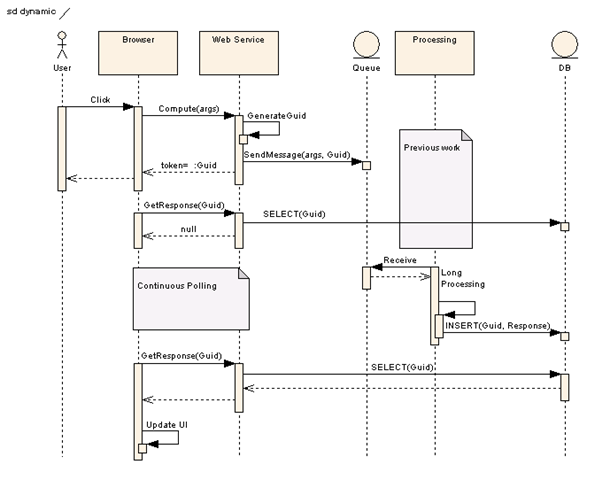
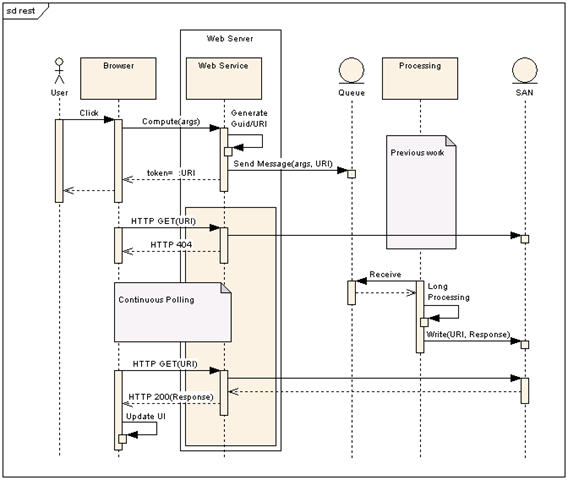


 If you've got a minute, you might enjoy taking a look at some of my best articles.
If you've got a minute, you might enjoy taking a look at some of my best articles. If you'd like to get new articles sent to you when they're published, it's easy and free.
If you'd like to get new articles sent to you when they're published, it's easy and free. Follow me on Twitter @UdiDahan.
Follow me on Twitter @UdiDahan.





July 30th, 2008 at 7:57 am
Could this not be handled using Asynchronous Pages in ASP.NET (see http://msdn.microsoft.com/en-us/magazine/cc163725.aspx ), as I understand it this technique works with WCF services as well….
July 30th, 2008 at 8:27 am
Klaus,
I actually have another sample with nServiceBus that demonstrates that, but it only works for ASP.NET pages. If you want to call the web service directly from the browser, there is no async model set up.
July 31st, 2008 at 5:57 am
What process cleans up all the static resources?
July 31st, 2008 at 2:02 pm
Like Mike said — you’d have to have something clean up the static files after a while. In my experience, NTFS starts to have problems when you’ve got 10,000+ items in a directory, so depending on your transaction volume, you’d need to run the cleanup possibly several times during the day. As well as schedule your defragger to run.
The trick would be knowing when an item becomes eligible for cleanup. I’m not sure you can delete it immediately after a successful (non-404 response) status request from the user (assuming you can even detect that under IIS, I don’t know). You might want to give them a little more time in case they have system problems at their end.
July 31st, 2008 at 5:55 pm
[…] Scaling Long Running Web Services […]
July 31st, 2008 at 7:21 pm
[…] Udi Dahan has just posted an excellent blog post about long running web services. […]
August 2nd, 2008 at 3:07 am
Chiph,
You’re absolutely right – which is why the process which actually writes the response to the disk is the beginning of a saga which may have its final (delete) phase triggered either by a read, a certain number of reads, and/or time.
August 6th, 2008 at 9:18 am
I love this solution especially the REST piece. I have a system where sometimes the web service operation will complete in a minute or two and other times it may run for four hours. Your solution is a perfect fit. I have one question though – since the operation results are retrieved via plain vanilla HTTP GET’s how would you document/communicate the content of an operations result. Currently I use data contracts to describe the XML schema for the data I return. If I use the REST approach you outline would you continue to use the data contract to document the schema of the result or would you leave the result structure out of the WSDL and communicate the form through supplemental documentation?
In some cases I could see leaving the schema out of the contract because it makes it easier to add elements in future releases without breaking existing code.
August 9th, 2008 at 3:30 pm
Dan,
Glad you like it. Let me know how it works out for you.
I use XSD to define the structure of the data returned. Sometimes additional documentation is needed anyway.
BTW, the X in XML stands for eXtensible (which you already knew), but I’m just reiterating that to say that it is quite easy to add elements in future releases without breaking existing code.
August 12th, 2008 at 2:47 pm
Great stuff
I wondered if you’d looked at the duplex WCF functionality that should help remove the need to do so much polling in Silverlight apps:
http://weblogs.asp.net/dwahlin/archive/2008/06/16/pushing-data-to-a-silverlight-client-with-wcf-duplex-service-part-i.aspx
It’s also really interesting reading this article. I worked on an XML over HTTP project many years ago that used many of these patterns for long running async jobs and it’s good to see you’ve adopted the same techniques.
August 13th, 2008 at 1:51 am
Colin,
I agree with the first commenter on that post – Rob.
IIS and ASP.NET are not designed to do comet in a scalable way.
There is the other problem of synchronous communication from server to client where server threads end up being blocked while waiting for the communication to succeed.
Hope that helps.
August 18th, 2008 at 9:33 am
@Udi
Good point on the threads, hadn’t thought that through.
Also I found this page quite interesting (particularly the distributed observer pattern near the end):
http://duncan-cragg.org/blog/post/distributed-observer-pattern-rest-dialogues/
August 19th, 2008 at 11:48 pm
Colin,
What he’s describing is using REST/HTTP to do messaging and pub/sub. I think that’s great. However, from a “how do I get my head thinking the right way” perspective, I find that plain messaging and pub/sub is simpler to grasp. Once you understand the applicative protocol you want to set up, mapping that to resources and GETs and POSTs isn’t very difficult.
Does that make sense?
September 3rd, 2008 at 3:49 pm
@Udi
Yeah it definitely makes sense but I have one more question, do you use REST in your architectures and if so how do you find it works alongside SOA and DDD?
September 3rd, 2008 at 10:00 pm
Colin,
I do use REST where it makes sense – but primarily as a kind of message serialization mechanism.
September 5th, 2008 at 12:36 pm
Hi Udi,
I listened to your latest DNR episode and after reading this post I must say that this is a really awesome approach. Thx for sharing.
I have a small nitpicking question though: what about security of the response resources (supposing that they contain sensitive information, which is not unlikely). I know its not easy to determine a GUID on the right time (before deleting the resource), but those kid hackers of today can do just about anything. Any thoughts about this topic?
Again, great stuff.
September 6th, 2008 at 2:56 am
Jan,
Glad you liked it.
Security is a big topic. The question is what threat profile we’re trying to protect against.
One option is for the same saga that created the resource to protect it with an ACL.
The thing is that you need to understand that probably the only way for an external attacker to know the guid/uri of the resource is for them to go for a man-in-the-middle attack. You’d need HTTPS to protect against that. Once you have that on the request, and you don’t allow anyone to list the response resources, you’re probably secure enough not to need HTTPS on the response.
September 10th, 2008 at 7:24 am
How about using an async HTTP handler with your restful stuff. This way you are not wasting _bandwidth_ (far more expensive than CPU/Memory resources).
I.e.
string MyWSStart(string bla) -> Returns URL “wswait.ashx?id=100”.
Open connection to wswait.ashx and wait for response.
string MyWSEnd() -> Returns result.
I will have it up on my blog at http://www.geekswithblogs.net/jcdickinson/ in a few minutes.
December 19th, 2008 at 11:29 pm
Udi
Love this approach. Were all the UI requests including more passive kinds of data (enumerated lists of regions for example) also handled by this single architectural approach in this scenario?
December 20th, 2008 at 2:55 am
Simon,
“Passive kinds of data”, like countries, regions, etc were done in a similar manner.
The main difference was that they had a well known URI ahead of time as well as longer cache timeouts. Regardless, when that data was changed on the server, it would also update that resource/URI.
June 1st, 2009 at 1:31 am
[…] read about how one could do this over at Udi Dahan’s blog, but this seems like a bad practice to me, most importantly – it uses polling. Most people seem to […]
July 1st, 2015 at 4:42 pm
Hi Udi,
It is now 7 years since you posted this, and still it reigns as one of the top Google search results for “long running web services”.
Given the advent of web sockets, does your recommendation for long running services with polling still stand?
July 11th, 2015 at 8:24 pm
Dan,
You can use things like SignalR to push back to the client.